This app packages Redash
About
Redash is our take on freeing the data within our company in a way that will better fit our culture and usage patterns.
Prior to Redash, we tried to use traditional BI suites and discovered a set of bloated, technically challenged and slow tools/flows. What we were looking for was a more hacker’ish way to look at data, so we built one.
Features
Redash was built to allow fast and easy access to billions of records, that we process and collect using Amazon Redshift (“petabyte scale data warehouse” that “speaks” PostgreSQL).
Today Redash has support for querying multiple databases, including: Redshift, Google BigQuery, PostgreSQL, MySQL, Graphite,
Presto, Google Spreadsheets, Cloudera Impala, Hive and custom scripts.
Redash consists of two parts:
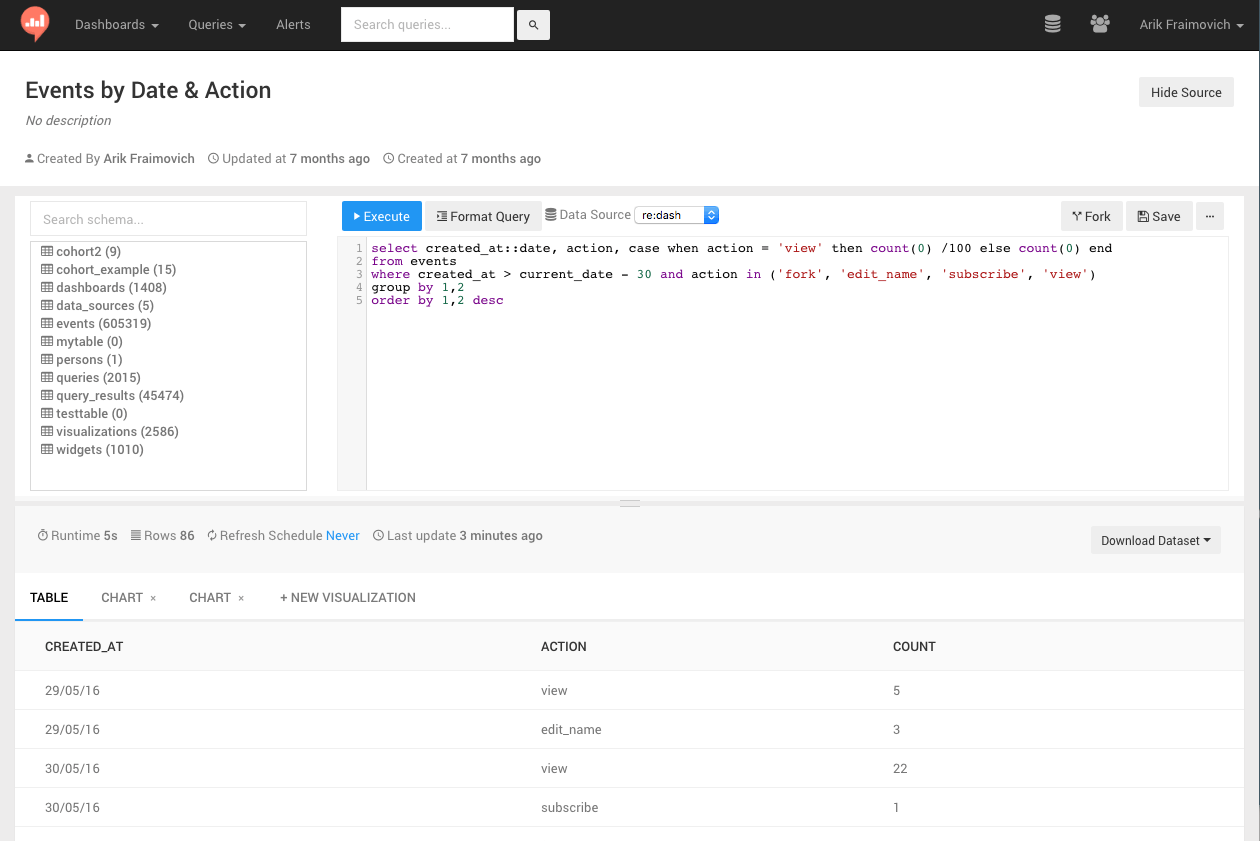
- Query Editor: think of JS Fiddle for SQL queries. It’s your way to share data in the organization in an open way, by sharing both the dataset and the query that generated it. This way everyone can peer review not only the resulting dataset but also the process that generated it. Also it’s possible to fork it and generate new datasets and reach new insights.
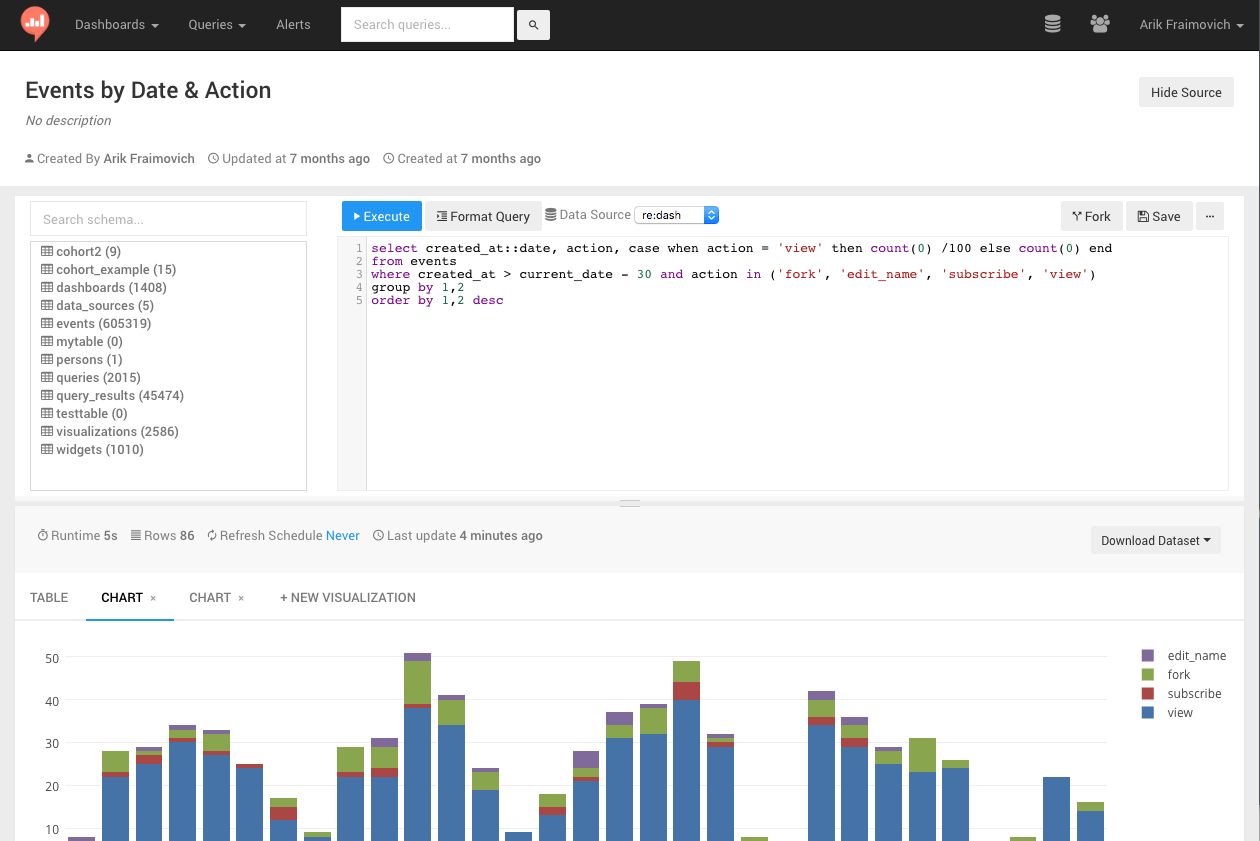
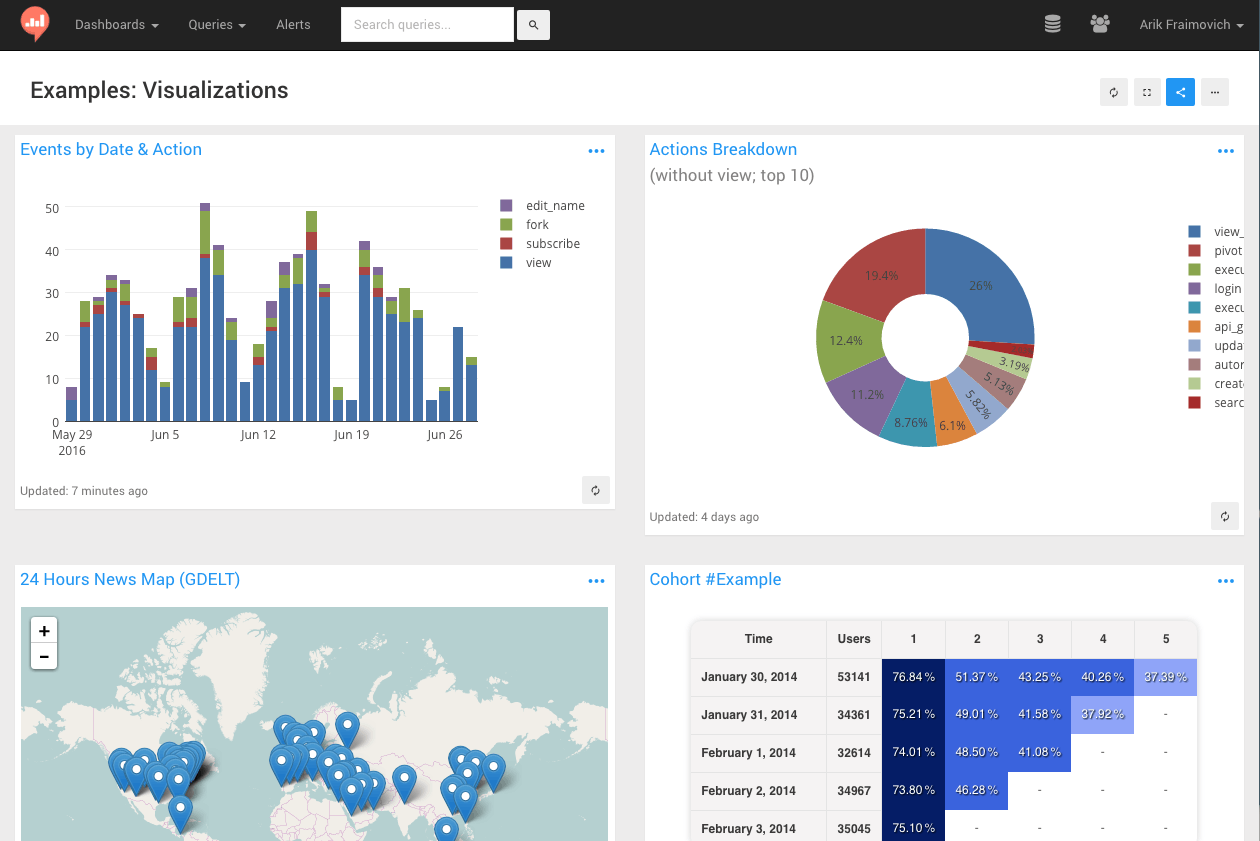
- Dashboards/Visualizations: once you have a dataset, you can create different visualizations out of it, and then combine several visualizations into a single dashboard. Currently it supports charts, pivot table and cohorts.